
AMD wants to talk about HSA, Heterogeneous Systems Architecture (HSA), its vision for the future of system architectures. To that end, it held a press conference last week to discuss what it's calling "heterogeneous Uniform Memory Access" (hUMA). The company outlined what it was doing, and why, both confirming and reaffirming the things it has been saying for the last couple of years.
The central HSA concept is that systems will have multiple different kinds of processors, connected together and operating as peers. The two main kinds of processors are conventional: versatile CPUs and the more specialized GPUs.
Modern GPUs have enormous parallel arithmetic power, especially floating point arithmetic, but are poorly-suited to single-threaded code with lots of branches. Modern CPUs are well-suited to single-threaded code with lots of branches, but less well-suited to massively parallel number crunching. Splitting workloads between a CPU and a GPU, using each for the workloads it's good at, has driven the development of general purpose GPU (GPGPU) software and development.
Even with the integration of GPUs and CPUs into the same chip, GPGPU is quite awkward for software developers. The CPU and GPU have their own pools of memory. Physically, these might use the same chips on the motherboard (as most integrated GPUs carve off a portion of system memory for their own purposes). From a software perspective, however, these are completely separate.
This means that whenever a CPU program wants to do some computation on the GPU, it has to copy all the data from the CPU's memory into the GPU's memory. When the GPU computation is finished, all the data has to be copied back. This need to copy back and forth wastes time and makes it difficult to mix and match code that runs on the CPU and code that runs on the GPU.
The need to copy data also means that the GPU can't use the same data structures that the CPU is using. While the exact terminology varies from programming language to programming language, CPU data structures make extensive use of pointers: essentially, memory addresses that refer (or, indeed, point) to other pieces of data. These structures can't simply be copied into GPU memory, because CPU pointers refer to locations in CPU memory. Since GPU memory is separate, these locations would be all wrong when copied.
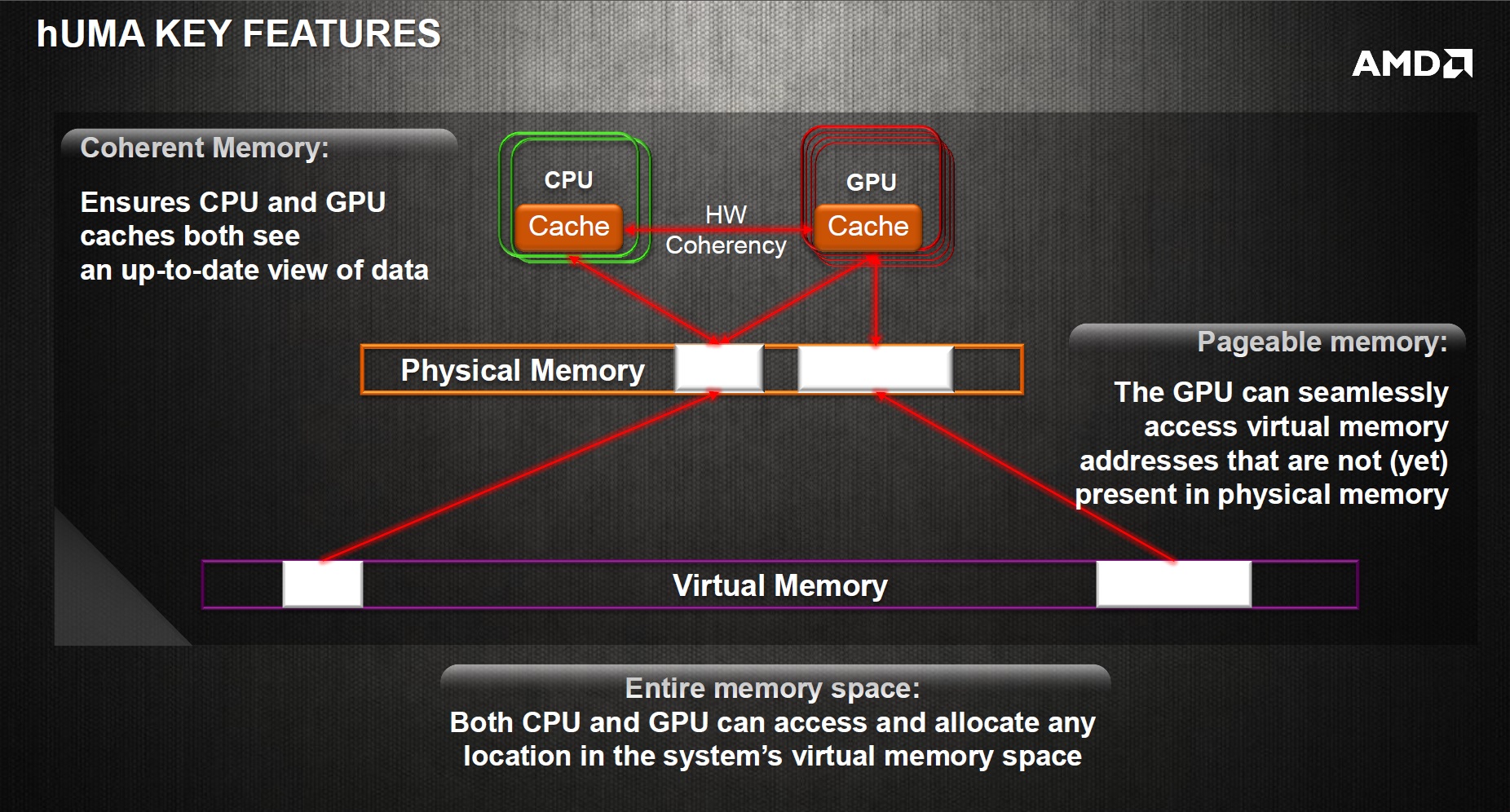
hUMA is the way AMD proposes to solve this problem. With hUMA, the CPU and GPU share a single memory space. The GPU can directly access CPU memory addresses, allowing it to both read and write data that the CPU is also reading and writing.
hUMA is a cache coherent system, meaning that the CPU and GPU will always see a consistent view of data in memory. If one processor makes a change then the other processor will see that changed data, even if the old value was being cached.
This is important from an ease-of-use perspective. In non-cache-coherent systems, programs have to explicitly signal that they have changed data that other processors might have cached, so that those other processors can discard their stale cached copy. This makes the hardware simpler, but introduces great scope for software errors that result in bugs that are hard to detect, diagnose, and fix. Making the hardware enforce cache coherence is consistent with AMD's motivation behind HSA: making it easier for developers to use different processor types in concert.
The memory addresses used in the CPU are not, in general, addresses that correspond to physical locations in RAM. Modern operating systems and software all use virtual memory. Each process has its own private set of addresses. Whenever an address is accessed, the CPU maps these virtual memory addresses to physical memory addresses. The set of virtual addresses can be, and often is, larger, in total, than the amount of physical memory installed on the system. Operating systems use paging to make up the difference: memory from some virtual addresses can be written out to disk instead of being kept in physical memory, allowing that physical memory to be used for some other virtual address.
Whenever the CPU tries to access a virtual address that's been written out to disk, rather than being resident in physical memory, it calls into the operating system to retrieve the data it needs. The operating system then reads it from disk and puts it into memory. This system, called demand-paged virtual memory, is common to every operating system in regular use today.
It is, however, a problem for traditional CPU/GPU designs. As mentioned before, in traditional systems, data has to be copied from the CPU's memory to the GPU's memory before the GPU can access it. This copying process is often performed in hardware independently of the CPU. This makes it efficient but limited in capability. In particular, it often cannot cope with memory that has been written out to disk. All the data being copied has to be resident in physical RAM, and pinned there, to make sure that it doesn't get moved out to disk during the copy operation.
hUMA addresses this, too. Not only can the GPU in a hUMA system use the CPU's addresses, it can also use the CPU's demand-paged virtual memory. If the GPU tries to access an address that's written out to disk, the CPU springs into life, calling on the operating system to find and load the relevant bit of data, and load it into memory.
Together, these features of hUMA make switching between CPU-based computation and GPU-based computation much simpler. The GPU can use CPU data structures and memory directly. The support for demand-paged virtual memory means that the GPU can also seamlessly make use of data sets larger than physical memory, with the operating system using its tried and true demand paging mechanisms.
As well as being useful for GPGPU programming, this may also find use in the GPU's traditional domain: graphics. Normally, 3D programs have to use lots of relatively small textures to apply textures to their 3D models. When the GPU has access to demand paging, it becomes practical to use single large textures—larger than will even fit into the GPU's memory—loading the portions of the texture on an as-needed basis. id Software devised a similar technique using existing hardware for Enemy Territory: Quake Wars and called it MegaTexture. With hUMA, developers will get MegaTexture-like functionality built-in.
AMD has needed HSA for a long time. The Bulldozer processor module, introduced in late 2011, paired two integer cores to a single shared floating point unit. Each core pair can run two threads, but if both threads make intensive use of floating point code, they have to compete for that shared floating point unit.
AMD's theory was that floating point-intensive code would use the GPU, so the relative lack of floating point power in the CPU wouldn't matter. But that didn't happen and still hasn't happened. There are several reasons for this, but one of the biggest is the inconvenience and inefficiency of mixing between CPU and GPU code, due to the memory copying and pinning that has to take place. HSA eliminates these steps. While this still doesn't make programming the GPU easy—many programmers will have to learn new techniques to take advantage of their massively parallel nature—it certainly makes it easier.
The first processor to come to market with HSA hUMA is codenamed Kaveri. It will combine 2-3 compute units (two integer cores, but shared floating point) using AMD's Bulldozer-derived Steamroller cores with a GPU. The GPU will have full access to system memory.
Kaveri is due to be released some time in the second half of the year.
HSA isn't just for CPUs with integrated GPUs. In principle, the other processors that share access to system memory could be anything, such as cryptographic accelerators, or programmable hardware such as FPGAs. They might also be other CPUs, with a combined x86/ARM chip often conjectured. Kaveri will in fact embed a small ARM core for creation of secure execution environments on the CPU. Discrete GPUs could similarly use HSA to access system memory.
The big difficulty for AMD is that merely having hUMA isn't enough. Developers actually have to write programs that take advantage of it. hUMA will certainly make developing mixed CPU/GPU software easier, but given AMD's low market share, it's not likely that developers will in any great hurry to rewrite their software to take advantage of it. We asked company representatives if Intel or NVIDIA were going to implement HSA. We're still awaiting an answer.
The company boasts that its HSA Foundation does have wide industry support, including ARM Ltd, major ARM vendors Qualcomm, Samsung, and TI, and embedded graphics company Imagination. If this set of companies embraced HSA, it's certainly possible that we could see it become a standard feature of the ARM systems-on-chips that power so many tablets and smartphones. What's not clear is how this would do much to help AMD, given its minor position in the tablet market and non-existent place in the smartphone market.
AMD's penultimate slide did point to one possible (though potentially temporary) salvation: games consoles. The PlayStation 4, released later this year, will contain an AMD CPU/GPU. It's widely believed that the next generation Xbox will follow suit. Though there's no official news either way, it's possible that one or both of these processors will be HSA parts. This will give AMD a steady stream of income, and also ensure that there's a steady stream of software written and designed for HSA systems. That in turn could provide the impetus and desire to see HSA used more widely.
Update: A reader has pointed out that in an interview with Gamasutra, PlayStation 4 lead architect Mark Cerny said that both CPU and GPU have full access to all the system's memory, strongly suggesting that it is indeed an HSA system.
reader comments
123